はじめに
マルウェアによる被害は未だ衰えず、その被害に関する報道を耳にしたことはあると思います。
マルウェアの数や種類は年々増加しており、人手で解析できる数を超えてしまっています。そのため、シグネチャベースの検知だけでなく機械学習を用いた検知も一般的になっています。
今回はマルウェア動的解析結果から抽出されたAPIコールを特徴量として、マルウェア検知システム(TransformerとLSTM)を構築していきます。
マルウェア検知に用いる特徴量をどのように取得するのかなど、マルウェア検知ドメイン特有の知識にも軽く触れつつ、マルウェア検知と機械学習の融合分野に馴染みのない方でも一からマルウェア検知システムを構築していけるように解説していきます。
マルウェア解析手法
マルウェア解析手法には大きく分けて静的解析と動的解析の2種類が存在しています。
以下の表にそれぞれの解析手法の比較を示します。
| 比較項目 | 静的解析 (Static Analysis) | 動的解析 (Dynamic Analysis) |
|---|---|---|
| 定義 | ファイルを実行せずに、コードや構造を解析する | サンドボックス等の隔離環境で実際に実行して挙動を追う |
| 主な手法 | バイナリ確認、逆コンパイル、文字列抽出(Strings) | API呼び出しの監視、通信ログ、レジストリ変化の追跡 |
| メリット | ・感染リスクがなく安全 ・解析スピードが非常に速い ・コード全体のロジックを網羅的に確認できる | ・難読化やパッキング(圧縮)の影響を受けにくい ・実際に発生する悪意ある挙動を直接確認できる |
| デメリット | ・難読化やパッキングされていると解析が困難 ・実行時に生成されるコードや挙動は追えない | ・解析環境(VM等)を検知して動作を止める検体がある ・解析に時間がかかる ・実行されない条件分岐先の挙動は確認できない |
| 解析時間 | 短い(数秒〜数分) | 長い(数分〜数十分) |
| 安全性 | 非常に高い(実行しないため) | 注意が必要(環境構築と隔離が必須) |
この表を見ると、それぞれにはメリットデメリットが存在しており、一概にどちらの解析手法が優れているという訳ではないことが分かります。
従って、どちらの解析手法も活用していく事が望ましいですが、マルウェア検知を機械学習で行う研究では、どちらかの手法から得られた特徴量を用いて検知を行うという状況設定が多いです。
- これは静的解析を扱うモデルと動的解析を扱うモデルの統合自体が一つの課題になりえることと、公開されているデータセットの多くが、単一の特徴量のみしか提供していないことなどの要因が考えられると思います。
動的解析から得られる特徴量
動的解析は実際の挙動を監視するので様々な情報が取得できます。例えば以下の通りです。
- 生成される子プロセスの情報
- 通信に関する挙動
- ファイルに関する挙動(作成、書き込みなど)
- レジストリに関する挙動(作成、書き込みなど)
- APIコールの呼び出し状況
今回は、動的解析から得られるAPIコールに着目してマルウェア検知を試みます。
- 簡単にAPIコールとはそもそも何かを説明します。APIコールはプログラムが「ファイルを開く」などOSの権限が必要な操作をOSにお願いする依頼のことです。例えばファイルを開く為のAPIはCreateFileです。APIそれぞれについての詳しい情報は、公式が提供しているドキュメントを参照してください。 https://learn.microsoft.com/ja-jp/windows/win32/api/fileapi/nf-fileapi-createfilea#syntax
モデルアーキテクチャ
APIコールはOSに対する依頼であると簡単に述べましたが、実際の挙動を追っていくと
「ファイルを開く」、「ファイルを読む」、「ファイルを閉じる」の様にプログラムがどういう依頼をOSに出していたのかが時系列データとして得られることになります。
プログラムが悪意ある挙動をしていた場合、その挙動の記録がAPIコールの順序(時系列データ)に現れる為、有効な特徴量としてマルウェア検知に広く用いられています。
時系列データを処理するアーキテクチャとしてLSTMやTransformerがあり、今回はこれらのモデルでのマルウェア検知性能の比較を行います。
マルウェア検知をAPIコールを使って行う試みには長い歴史があり、利用されてきたモデルの変遷には自然言語処理の進化も関係しています。かつてはBoWやWord2Vecなどの技術をAPIコールに適用する研究もありました。現在ではGPTなどの成功をもたらしたTransformerを適用する研究が多い印象です。事前学習やファインチューニングをAPIで行う研究もあります。
データセット
本記事の検証には、以下の論文で公開されている「MalbehavD-V1」データセットを使用しました。
-
Paper: Pascal Maniriho, Abdun Naser Mahmood, Mohammad Jabed Morshed Chowdhury, “API-MalDetect: Automated malware detection framework for windows based on API calls and deep learning techniques,” Journal of Network and Computer Applications, 103704, 2023.
-
Dataset: MalbehavD-V1 (GitHub)
-
総サンプル数: 2,570件
- マルウェア: 1,285件(VirusTotalから収集、2021年第2四半期に提出されたもの)
- 正常ファイル (Benign): 1,285件(CNETから収集し、VirusTotalで安全性を確認済み)
-
ラベル構成: 1:1の完全な均衡データ(バランスデータ)となっており、学習時の偏りが起きにくい構成です。
データは、隔離された環境(サンドボックス)で実際にファイルを実行して得られた挙動に基づいています。
- 解析環境: Cuckoo Sandbox
- 仮想化: Oracle VirtualBox
- OS: Windows仮想マシン
クラス不均衡が無い点と、サイズがそこまで大きくない為、Google Colabでも十分検証可能であったのでこのデータセットを選択しました。
検証
検証はGoogle Colabで行います。
使用したコードはgithubに公開してあります。https://github.com/konseclab/malware-detection-api-transformer-vs-lstm/tree/main
ここでは主にマルウェア検知に用いるAPIデータセットの中身がどうなっているかの確認と、簡単なデータ処理方法について説明します。
データセットの中身
=== ステップ1: データセットの全体像 ===
# 1. データの読み込み
df = pd.read_csv('MalbehavD-V1/MalBehavD-V1-dataset.csv')
print("=== ステップ1: データセットの全体像 ===")
print(f"データの総数 (行, 列): {df.shape}")
print("- 行: 解析したファイル(検体)の数")
print("- 列: ハッシュ値、ラベル(1/0)、および時系列順のAPIコール")データの総数 (行, 列): (2570, 177)
- 行: 解析したファイル(検体)の数
- 列: ハッシュ値、ラベル(1/0)、および時系列順のAPIコール
=== ステップ2: ラベルの分布確認 ===
print("\n=== ステップ2: ラベルの分布確認 ===")
label_counts = df['labels'].value_counts()
print(f"0 (Benign/正常): {label_counts[0]}件")
print(f"1 (Malware/マルウェア): {label_counts[1]}件")0 (Benign/正常): 1285件 1 (Malware/マルウェア): 1285件
=== ステップ3: テキストの数値化 (Label Encoding) ===
print("=== ステップ3: テキストの数値化 (Label Encoding) ===")
#機械学習を行うにあたって、API名は数値に置き換える必要があります。一つ一つのAPIに番号を振ると考えてください。
# 1. 全てのAPI名を1つのリストにして「辞書」を作る
all_apis = api_sequences.flatten()
le = LabelEncoder()
le.fit(all_apis)
# 2. 文字列のシーケンスを数字のシーケンスに変換
encoded_sequences = np.array([le.transform(seq) for seq in api_sequences])
print(f"学習したAPIの種類数 (Vocab Size): {len(le.classes_)}")
print(f"API名の例 (最初の10個): {le.classes_[:10]}")
# 変換前後の比較を表示
print("\n--- 変換の具体例 (最初の10件) ---")
comparison_df = pd.DataFrame({
'Original API Name': api_sequences[0][:10],
'Encoded Integer': encoded_sequences[0][:10]
})
display(comparison_df)学習したAPIの種類数 (Vocab Size): 292
API名の例 (最初の10個):
['CertControlStore' 'CertCreateCertificateContext' 'CertOpenStore'
'CertOpenSystemStoreW' 'CoCreateInstance' 'CoCreateInstanceEx'
'CoGetClassObject' 'CoInitializeEx' 'CoInitializeSecurity'
'CoUninitialize']変換の具体例 (最初の10件)
| No. | Original API Name | Encoded Integer |
|---|---|---|
| 0 | LdrUnloadDll | 133 |
| 1 | CoUninitialize | 9 |
| 2 | NtQueryKey | 180 |
| 3 | NtDuplicateObject | 160 |
| 4 | GetShortPathNameW | 86 |
| 5 | GetSystemInfo | 89 |
| 6 | IsDebuggerPresent | 129 |
| 7 | GetSystemWindowsDirectoryW | 93 |
| 8 | NtClose | 149 |
| 9 | GetFileVersionInfoSizeW | 80 |
データ処理の流れ
Transformerでのデータの処理は以下の通りです。細かい設定についてはコード参照願います。
[ 入力: APIのIDの列 ]
↓
[ Embedding層 ] (vocab_size × 64)
※ ここに埋め込み行列がある
↓
[ Positional Encoding ] (位置情報をプラス)
↓
[ Transformer Encoder層 (1段目) ]
※ nhead=8 で相互関係を計算
↓
[ Transformer Encoder層 (2段目) ]
※ num_layers=2
↓
[ Global Average Pooling ]
※ シーケンス全体の平均をとる
↓
[ 全結合層 (fc) ] (64次元 → 2次元へ変換)
↓
[ 出力: 判定結果 ]結果
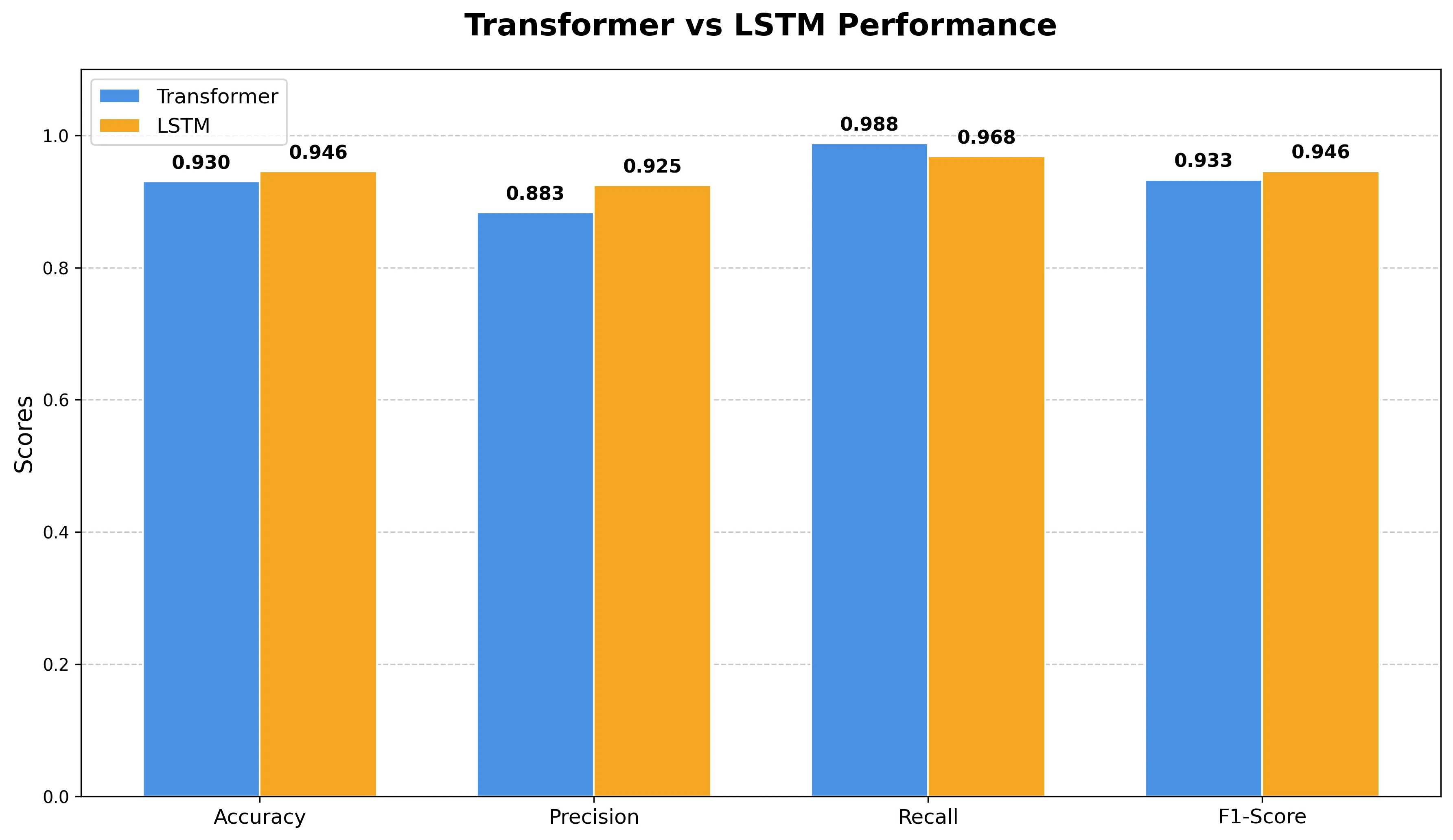
それでは、LSTMとTransformerでの検知性能比較をしていきます。
まずは正解率とF1スコアを見てみます。
| モデル | 正解率 (Accuracy) | F1スコア |
|---|---|---|
| LSTM | 0.9455 | 0.95 |
| Transformer | 0.9300 | 0.93 |
LSTMの方が僅かですがACCとF1スコアが高いですね。
次は判定対象ごとのPrecision, Recallを見てみます。
| モデル | 判定対象 | 適合率 (Precision) | 再現率 (Recall) | F1スコア |
|---|---|---|---|---|
| LSTM | Benign (正常) | 0.97 | 0.92 | 0.95 |
| Malware (マルウェア) | 0.92 | 0.97 | 0.95 | |
| Transformer | Benign (正常) | 0.99 | 0.87 | 0.93 |
| Malware (マルウェア) | 0.88 | 0.99 | 0.93 |
TransformerのMalwareに対するRecallを見ると、ほぼすべてのマルウェアの検知ができています。
悪意のある挙動により強く反応する様に学習されたと考えられます。
今回の検証でTransformerに比べてLSTMの方がACCとF1スコアが高かったのは、今回のタスクがそこまで長い文章量を扱うものではなく(最大175)、データセットのサイズも比較的小さめだったことが起因しているかもしれません。
ただ今回の検証ではTransformerは2層であり、ベクトル埋め込み次元数を含めパラメータ調整をしていない為、どちらのモデルに関しての検証にしても不十分である点には注意しないといけません。あくまでAPIコールでマルウェア検知を体験することが目的の検証です。
最後にマルウェアの検知精度を棒グラフで眺めて検証を終わりとします。
おわりに
マルウェア検知は本当に多くの手法が存在しており、今回検証したものはほんの一部です。
そして現在のマルウェアと機械学習の融合分野に関する研究は、検知性能だけではなく、どうしてそれをマルウェアであると判断したのかを説明する解釈性、マルウェア検知システムを掻い潜ろうと画策する敵対性サンプルへの対処など面白い課題が多く存在しています(これらについてもいつか記事にしたいです)。
この記事がマルウェア×機械学習の分野に興味を持つ一因となれば幸いです!
今回用いたコードはGoogle Colabolatoryで実行可能ですので、是非皆さんも手元でマルウェア検知を体験してみてください。